**Update:** Dropbox came through with a CSV containing the date, status, and full path to the file. Basically everything I asked for in the support request, and in just under 24 hours.
Dropbox recently discovered that their software lost user data. If you were affected, you probably received an email that started out like this:
> We’re reaching out to let you know about a Selective Sync issue that affected a small number of Dropbox users. Unfortunately, some of your files were deleted when the Dropbox desktop application was shut down or restarted while you were applying Selective Sync settings.
This sucks. It sucks for users, and it sucks for Dropbox. I know the gut wrenching cliff-dive of emotion that comes when you discover you’ve lost user data. I get it, but when you screw up like this, you have to go above and beyond in assisting recovery. Dropbox’s response hasn’t been horrible, but there’s more they can do to help users recover files.
I backup my data. I have a local [Time Machine backup](http://support.apple.com/kb/ht1427) that goes back about 18 months, and I use [Backblaze](https://www.backblaze.com) for remote backups. Dropbox indicates that the files were deleted about 7 months ago. Theoretically this means I should be able to recover any file that Dropbox lost.
Unfortunately, the format in which Dropbox provides lost file information makes recovery a very tedious process. In the notification email, Dropbox provides a link to their website where you can view details about the lost files. This is what the resulting page looks like:

*Note: The black boxes are redaction intended to keep at least some semblance of privacy with regard to the information I’m sharing here.*
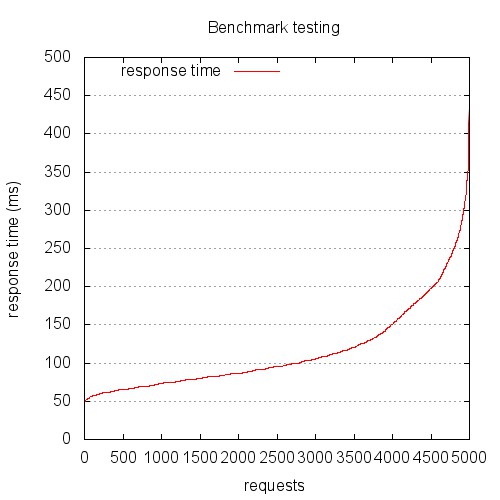
Let’s tally up our losses:
616 – 385 + 27 = 258
36 – 19 + 3 = 20
Total: 278
Knowing the damage, we must dive in to the next step: recovery. In order to recover a file, you need — at a minimum — the full name of the file that was lost. Ideally, you also know the full path to the file. Let’s see what details Dropbox has provided. Clicking the “385/616 files” link brings up this page:

A browsable interface. This helps me get oriented with what was lost, but I would very much prefer *not* to dig through a nested list of folders to identify almost three hundred lost files. In an effort to find a more comprehensive and machine parsable list, my eye was drawn to the “231 files” link. This is what I get:
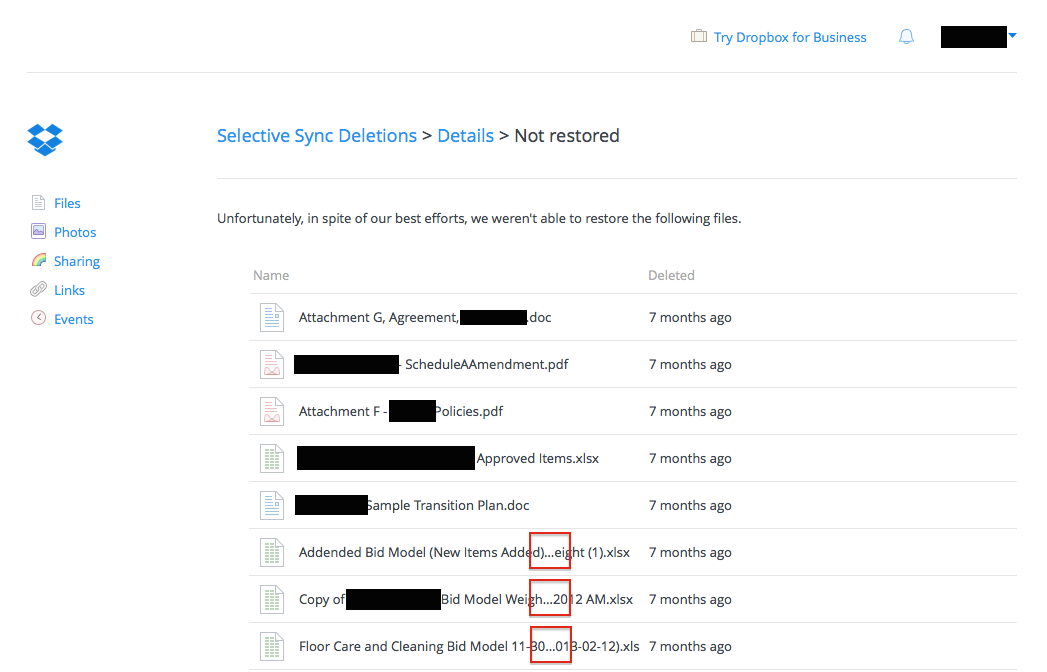
This is, frankly, a disaster. From the perspective of an IT person attempting recovery:
1. The filenames are incomplete (note the ellipses marked with red boxes).
2. There is no way to download this list.
3. There is no file path information provided.
4. The deletion date is a relative date.
Nearest I can tell, Dropbox has provided no means for IT staff to access a list of lost files that is useful for automated recovery. I submitted a support request to Dropbox, explaining much of the same information as I have posted here. If you were affected by the selective sync data loss issue, I’d appreciate it if you would send a similar request. The more requests they receive, the more likely we are to get something usable for mass-recovery.
>I recently received notification that a couple hundred of our files were lost due to a selective sync issue. What’s done is done. We build software too, so I understand how much this must suck for your team, but we’re working on recovery, and I think Dropbox can do more to help.
>
>We have backups of all our lost files, so I can perform a recovery, but the format Dropbox has provided information in isn’t usable by our IT department. A browsable format is nice for end-users, but from an IT recovery perspective, we could use the following in some machine parseable format (JSON, CSV, TSV, etc):
>
>* File name
>* Dropbox path to file
>* Status (un-recovered, restored, restored wrong version)
>* Date deleted (the actual date, not a human-friendly relative date)
>
>This list would benefit internal IT departments, as well as end-users who contact an IT support professional to assist with the recovery of lost files.
>
>Thanks,
>Brad